I hadn’t written in a while and to get over my writer’s block, I decided to pick up a small weekend project and have some fun with it.
I started with embeddings and tried to think of them as a space you could move through. Each word becomes a node and the goal is to get from a start word to a target word through small semantic steps.
I embedded a dataset of common words and treated the whole thing as a graph traversal problem using A* search algorithm.
The Basic Idea
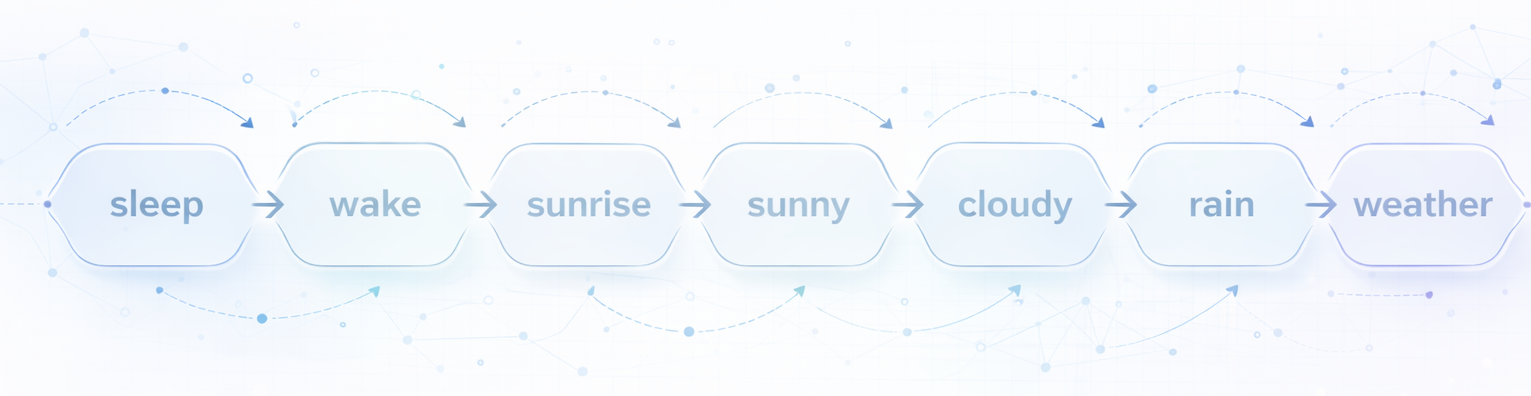
The concept is simple: given two words like “sleep” and “weather”, can we find a semantic ladder between them? Each step moves through words that are semantically close to each other. Something like:
sleep → wake → sunrise → sunny → cloudy → rain → weather
You can try it out here: https://huggingface.co/spaces/thameena/semantic-word-ladder
Source Code: Github
Turning Words Into Vectors
all-MiniLM-L6-v2 from the sentence-transformers library was used to convert words into embeddings where each word is represented as a 384 dimensional vector. Words with similar meanings tend to cluster together in this space. “King” and “Queen” end up close. “King” and “Bicycle” do not.
Similarity between two words is measured using cosine similarity, which checks how aligned two vectors are. A score of 1 means identical, 0 means unrelated.
Here is what embedding the words looks like:
model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode(
words,
convert_to_numpy=True,
normalize_embeddings=True
)
The normalize_embeddings=True part is important. Normalizing a vector rescales it, so its magnitude becomes 1. This puts all vectors at the same distance from the origin and leaves only the direction to differ.
Cosine similarity computes the cosine of the angle between two vectors, which normally involves dividing by their magnitudes.
cosine_similarity(a, b) = (a · b) / (||a|| · ||b||)
If all vectors already have magnitude 1, that division drops out of the equation. In that case, the dot product becomes the cosine similarity. In other words, normalization ensures that similarity depends only on direction (semantic meaning) and not on vector length.
Once the embeddings are generated, I saved them locally, so that it need not be recomputed them every time. I also created a lookup dictionary that maps each word to its index in the embedding matrix.
Navigating the Space: A* Search
The next question is, how do we actually find a path from “sleep” to “weather”.
Here we need to treat the embedding space like a graph. Each word would be a node and edges connect words that are semantically similar. But instead of building the entire graph, we can generate neighbors on the fly using FAISS (more on this below).
This now becomes a classic graph traversal problem. I first tried a greedy algorithm. At each step, just pick whichever neighbour is closest to the target. It worked sometimes, but not always. If the current word’s neighbors doesn’t move semantically towards the target, greedy search has no way to backtrack and try something else. It just gets stuck.
That’s the core problem A* solves. Rather than committing to one word and moving on, it keeps a priority queue of all candidate words seen so far, ranked by:
f(n) = g(n) + h(n)
- g(n) is steps taken so far
- h(n), the heuristic function, is the estimated distance remaining, calculated by
1 - cosine_sim(current_word, target_word)
Words that are both reachable in few steps and semantically close to the target get explored first. If a branch leads somewhere unpromising, it falls down the queue and a different candidate gets explored instead, something that a greedy algorithm doesn’t do.
Finding Nearest Neighbors: FAISS
At each step of the search, we need the k most similar words to the current word. With a vocabulary of 10,000 words, a simple dot product over all vectors would work fine. But I used FAISS, a library from Meta, built for nearest-neighbor search in high-dimensional spaces. This becomes necessary at the scale of millions of vectors, where brute-force cosine similarity search gets slow.
My initial plan was to use a vector database like ChromaDB, but the problem turned out to be simpler. The vocabulary is fixed and all embeddings live in memory, so I only needed fast nearest-neighbor lookups. FAISS fits that use case better.
The full graph is not built upfront. Instead, when the A* search algorithm needs to know which words are semantically close to the current word, it queries FAISS on the fly:
def get_neighbours(word: str, k: int = 5):
# Get the embedding for the word
# Query FAISS for k nearest neighbors
# Return the list thats sorted by similarity
The Final Result
I wrapped everything in a Streamlit app and deployed it on Hugging Face Spaces. You can adjust how many neighbors to consider at each step, type in any start and end word and watch the algorithm find a semantic path between them. Hugging Face Spaces: https://huggingface.co/spaces/thameena/semantic-word-ladder